어시다시피 GPT모댈은 언어룰 이해하는데 뛰어난 인공지능 모댈입니다. 여기서 언어를 이해한다는 점에 주목해 주세요.
우리가 대화를 할 때 중요한 전제는 두가지 입니다. 첫째는 단기 기억입니다. 방금 말한 내용를 기억해야 대화가 매끄럽습니다. 불편한 예로 치매를 앓고 있는 분들과 대화가 쉽지 않은 이유입니다. 그 다음으로 문맥(context)을 이해하는 일입니다. 대화가 오고 가는 말귀를 알아 듣고 대화에 집중하게 합니다. 즉 대화중에 거시기하면 무슨 말인지를 알수 있어야 합니다. GPT모델은 이 점에 특화된 점으로 우리가 프롬프트로 AI와 대화가 가능하게 해 줍니다.
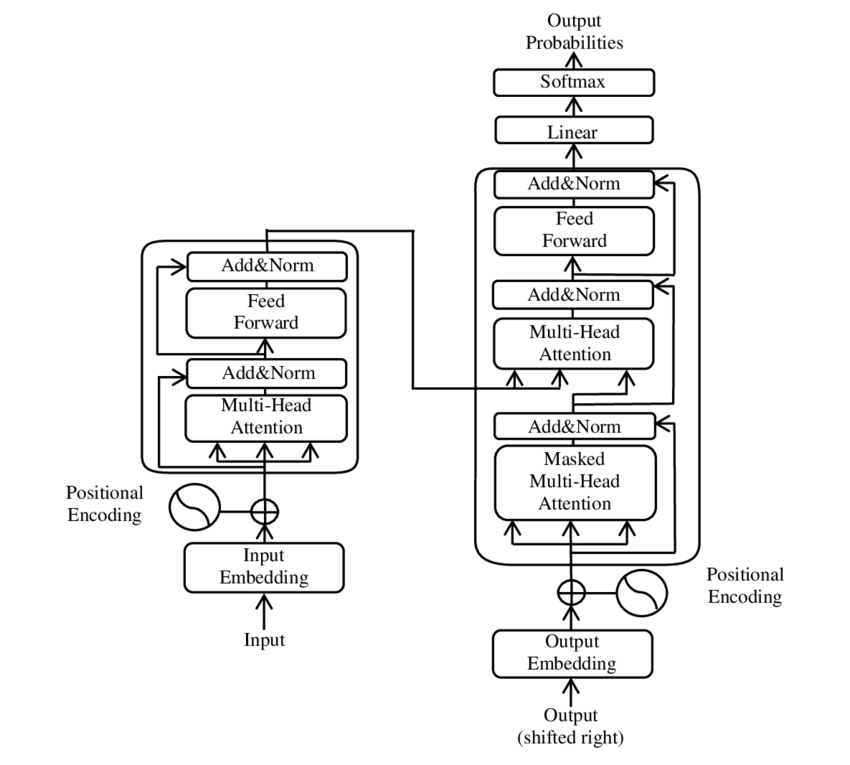
다음은 GPT모델에서 Transformer를 구성하는 여러 모듈입니다. 이 가운데 어텐션 모듈(attention module)이 문맥을 이해하고 대화를 원활하게 돕는 핵심 모듈입니다.
1. 입력 임베딩과 위치 인코딩 (Input Embedding & Positional Encoding):
* 원본 자료에서는 입력 임베딩을 통해 입력 시퀀스의 각 단어를 연속적인 벡터로 변환한다고 설명합니다. 또한, Transformer에는 순서에 대한 정보를 포함하기 위해 위치 인코딩(Positional Encoding)을 추가한다고 되어 있습니다 이 위치 인코딩은 sine과 cosine 함수를 사용하여 시퀀스의 각 단어의 위치 정보를 추가함으로써 순서의 의미를 인식하도록 돕습니다.
2. 멀티-헤드 어텐션 (Multi-Head Attention):
* 멀티-헤드 어텐션은 여러 개의 어텐션 헤드를 통해 입력 시퀀스의 서로 다른 부분을 동시에 주목할 수 있게 합니다. 원본에서는 **"다중 표현 서브스페이스에서 정보를 동시에 주목할 수 있게 한다"**고 설명하며, 이를 통해 모델이 다양한 맥락에서 정보를 학습할 수 있다고 합니다 이 방식으로 각 헤드는 다른 종류의 정보를 캡처하며, 최종적으로 모든 헤드의 출력을 결합하여 더 풍부한 표현을 생성하게 됩니다.
3. 자기 어텐션 (Self-Attention):
* 자기 어텐션(Self-Attention)은 동일한 시퀀스 내의 단어들 간의 관계를 찾아내는 것입니다. 원본에서는 "단일 시퀀스 내의 서로 다른 위치들을 연결해 시퀀스를 표현하는 방법"으로 자기 어텐션을 설명합니다. 이는 문장의 모든 단어가 다른 모든 단어와 연결될 수 있게 하여, 문맥적 이해를 깊게 해주는 중요한 요소입니다.
4. 피드-포워드 네트워크 (Feed-Forward Network):
* 피드-포워드 네트워크는 각 단어의 표현을 한 번 더 변환하는 역할을 합니다. 원본 자료에서는 "각 위치에서 동일하게 적용되는 두 개의 선형 변환과 ReLU 활성화 함수로 구성된 네트워크"로 설명합니다. 이 네트워크는 각 단어에 대해 독립적으로 적용되므로, 어텐션을 통해 얻은 정보를 더 고차원적으로 변환하고 강화시킵니다.
5. 인코더-디코더 어텐션 (Encoder-Decoder Attention):
* 인코더-디코더 어텐션은 디코더가 인코더의 출력 정보를 참조하여 새로운 단어를 생성할 때 사용하는 메커니즘입니다. 원본 자료에서는 **"디코더의 쿼리는 이전 디코더 레이어에서 나오고, 키와 값은 인코더 출력에서 온다"**고 설명하여, 디코더가 입력 시퀀스의 모든 위치를 참고할 수 있음을 강조하고 있습니다.
6. 마스크드 어텐션 (Masked Multi-Head Attention):
* 마스크드 멀티-헤드 어텐션은 디코더에서 사용되는 어텐션 메커니즘 중 하나로, 디코더가 이전에 생성된 단어들만 참고할 수 있도록 합니다. 원본에서는 "디코더의 자기 어텐션 서브레이어에서 미래 위치를 참조하지 못하게 한다"고 설명하며, 이는 모델이 올바른 순서대로 단어를 생성하도록 돕는 기능입니다
7. 출력 및 소프트맥스 (Output & Softmax):
* 출력 단계에서는 소프트맥스 함수를 사용하여 다음에 생성될 단어에 대한 확률을 계산합니다. 원본 자료에서는 **"출력 임베딩과 선형 변환 후 소프트맥스를 적용하여 다음 단어의 확률을 예측한다"**고 명시되어 있습니다.
결론:
위의 설명들은 원본 자료의 내용을 바탕으로 한 것이며, 이를 통해 각 모듈과 알고리즘이 협력하여 문맥을 깊이 이해하고 번역 등 다양한 작업을 수행하는 과정을 확인할 수 있습니다. Transformer의 주요 기능들은 모두 상호작용하며, 긴 문맥을 효과적으로 이해하고, 병렬 처리를 통해 빠르게 학습하는 것을 목표로 설계되었습니다.
각 모듈과 알고리듬이 어떻게 작동하는지를 쉽게 설명하기 위해서 하나의 팀이 협력하는 상황에 비유해서 설명해 볼게요.
예시: 팀 프로젝트 진행
Transformer 모델을 하나의 프로젝트 팀으로 생각해봅시다. 이 팀은 어떤 언어를 다른 언어로 번역하는 프로젝트를 맡았어요. 이 팀에는 여러 명의 전문가들이 있고, 각자 다른 역할과 능력을 가지고 있죠.
1. 입력 임베딩과 위치 인코딩 (Input Embedding & Positional Encoding):
* 입력 임베딩은 단어를 프로젝트 팀이 이해할 수 있는 코드나 심볼로 바꿔주는 과정이에요. 마치 프로젝트에서 처리해야 할 각 문서나 자료를 모두가 이해할 수 있도록 번역하는 것과 같아요.
* 위치 인코딩은 각 문서가 프로젝트 전체에서 어떤 순서에 있는지를 나타내는 거예요. 팀원이 서로 대화할 때 순서를 모르고 무작위로 말하면 혼란스럽겠죠? 위치 인코딩 덕분에 이 단어들이 어떤 순서로 나왔는지를 알 수 있어요.
2. 멀티-헤드 어텐션 (Multi-Head Attention):
* 멀티-헤드 어텐션은 마치 여러 팀원이 동시에 같은 문서의 다른 부분을 집중해서 보는 것과 같아요. 예를 들어, 한 팀원은 문서의 앞부분을, 다른 팀원은 뒷부분을 보면서 중요한 내용을 메모해요. 그러면 문서 전체에 대해 훨씬 깊은 이해를 할 수 있겠죠. 이렇게 서로 다른 시각에서 문서를 분석하고 난 다음에는 이 정보를 종합해서 더 풍부한 결과를 만들어내요.
3. 자기 어텐션 (Self-Attention):
* 자기 어텐션은 문서 내에서 각 단어가 다른 단어와 어떤 관계에 있는지를 파악하는 과정이에요. 마치 팀원이 보고 있는 특정 단어가 그 문서 안의 다른 어떤 단어들과 관련이 있는지를 찾아내는 거예요. 예를 들어, "학교"라는 단어가 나오면, "선생님", "학생", "수업" 같은 단어들과 관련이 있다고 이해하는 것이죠. 그래서 단어들이 서로 어떤 연결이 있는지를 파악함으로써 문장의 의미를 더 정확하게 이해할 수 있게 돼요.
4. 피드-포워드 네트워크 (Feed-Forward Network):
* 피드-포워드 네트워크는 팀원이 수집한 정보를 기반으로 분석을 깊게 하는 과정이에요. 여러 문서를 보고 난 후 팀원이 이를 바탕으로 결론을 내리고 더 심화된 정보를 제공하는 것과 비슷해요. 각 단어가 가지고 있던 기본적인 정보에서 더 많은 의미를 도출해내는 거죠.
5. 인코더-디코더 어텐션 (Encoder-Decoder Attention):
* 인코더-디코더 어텐션은 팀원이 번역 프로젝트를 할 때 기존 자료를 참고하는 것과 같아요. 입력(원본 문서)에서 중요한 정보들을 잘 분석한 후, 출력(번역된 문장)을 만들기 위해 그 정보들을 계속 참고하는 거예요. 예를 들어, 한 팀원이 원본 문서에서 "이 부분은 정말 중요하니까 꼭 번역에 반영해야 해"라고 다른 팀원에게 알려주는 것처럼, 디코더가 원본 문서의 정보를 참고해서 새로운 문장을 만들어내는 거죠.
6. 마스크드 어텐션 (Masked Multi-Head Attention):
* 마스크드 어텐션은 마치 팀원이 서로 발표할 때, 이전에 나온 내용만 참고하는 규칙을 지키는 것과 같아요. 발표하는 도중에 아직 말하지 않은 부분을 미리 알면 안 되니까, 이미 발표된 내용만 참고해서 다음 내용을 준비하는 거예요. 디코더에서 다음 단어를 예측할 때도 마찬가지로, 이미 생성된 단어들만 보면서 그다음에 나올 단어를 예측하게 만드는 거죠.
7. 출력 및 소프트맥스 (Output & Softmax):
* 마지막 단계는 팀이 모여서 최종 결론을 내리고 발표하는 과정이에요. 소프트맥스는 여러 가지 가능성 중에서 가장 적합한 선택을 확률적으로 고르는 과정이에요. 마치 팀원들이 여러 후보 중에서 가장 적절한 단어를 골라서 발표하는 것과 비슷해요.
요약하자면:
* Transformer는 각 팀원이 서로 협력하여 전체 문서를 분석하고 중요한 부분을 파악한 다음, 그 정보를 바탕으로 새로운 내용을 만들어내는 것과 비슷한 방식으로 작동해요.
* 어텐션은 각 팀원이 여러 시각에서 중요성을 파악하는 것, 피드-포워드 네트워크는 파악한 정보를 심화하는 것, 인코더-디코더 상호작용은 원본 문서를 잘 참고하며 번역하는 것을 의미하죠.
이런 식으로 각 모듈과 알고리즘이 협력하여 문맥을 깊이 이해하고, 최종적으로 정확한 번역이나 다른 작업을 수행하게 됩니다.
'AI 리서치' 카테고리의 다른 글
| AI Research Highlight 2025.03.30 (0) | 2025.03.30 |
|---|---|
| OpenAI의 SORA: 눈길을 사로잡는 비주얼 콘텐츠 제작 비법 (3) | 2024.12.19 |
| DisRanker: AI 검색의 게임 체인저, GPT의 힘을 BERT에 담다 🚀 (3) | 2024.11.10 |


